
With the lesson on arrays in the books, let’s go ahead and move on to one of its close relatives: the linked list. When it comes to data structures, the array’s biggest rival is the linked list. That’s because at a high level, they operate almost indistinguishably. After all, they’re both just one dimensional lists. However, under the hood they have very different implementations. In this lesson, we’ll cover exactly what those differences are and how those differences drive performance.
Table of Contents
- What is a Linked List?
- Properties of Linked Lists
- Applications of Linked Lists
- Java Linked List Syntax
- Summary
What is a Linked List?
Like an array, a linked list is a one dimensional list of elements. The primary difference with a linked list is that it doesn’t require us to define a size ahead of time. That’s because a linked list is not stored in contiguous spaces in memory. Instead, each element is stored in whatever space is free at the time of creation. This new element is then linked to the previous element via an object reference. This is accomplished using a structure known as a node.
A node is sort of like a boxcar in a train. Each boxcar contains some cargo which is linked to the boxcars around it. In code, a node might be defined as follows:
public class Node {
private Node next;
private int payload;
public Node(int payload, Node next) {
this.payload = payload;
this.next = next;
}
}
Typically, our payload would accept any data type, but generic types are a bit beyond the scope of this lesson. Instead, let’s stick with integers. Here we have a node which stores an integer and links to another node. As stated before, the beauty of this structure is that we don’t have to worry about a maximum list size. Instead, we can continually add nodes as needed. Eventually, we would end up with a structure that might look like the following:
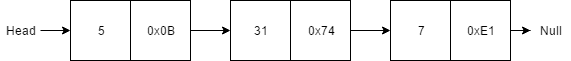
In this example, we have a list which contains three nodes. The left side of the node stores the payload while the right side of the node stores the reference to the next node.
As a side note, linked lists can also be doubly linked. In other words, each node would have a reference to the next node and the previous node. The main difference here is that we would be able to traverse the list from either end.
Properties of Linked Lists
Due to its structure, the linked list has some pretty interesting properties. For one, we don’t have the advantage of random access like arrays. If we want the third element in a list, we have to traverse the list to that node. That’s because we only have access to the first node in a linked list.
However, we do gain a few key benefits. For one, a linked list allows us to grow our data set forever. We no longer have a size restriction. Instead, we can just tack on a new node every time we want to make an addition. Likewise, deletions are extremely easy. We don’t have to shift elements around. We simply redo the linkages to eliminate the element we want to delete. Then we let the garbage collector clean up after us.
The two advantages above also imply that linked lists are friendly with memory. While each node does require extra space for the next node reference, we never use more space than we need. However, the structure of a linked list does tend to tank cache locality – the speed at which we can retrieve our data from memory – as the processor is unable to predict the next memory address during traversal.
Applications of Linked Lists
The power of a linked list comes from its dynamic size while its crux is its lack of random access. As a result, linked lists are useful when we don’t know how large our data set will be. Unfortunately, it’s pretty rare to see a linked list in production code. As we’ll learn later, Java has support for a data structure that is often more versatile and offers better performance: the ArrayList. That said, it’s still important to understand how a linked lists work as they usually serve as the basis for more complex data structures like stacks, queues, and hash tables.
Java Linked List Syntax
While Java does have support for linked lists in its collections library, we’re going to go ahead and implement a linked list here in code. That way we can see exactly how they work under the hood.
Class Definition
As shown before, a node is implemented as follows:
public class Node {
private Node next;
private int payload;
public Node(int payload, Node next) {
this.payload = payload;
this.next = next;
}
public Node getNext() {
return next;
}
public void setNext(Node next) {
this.next = next;
}
public int getPayload() {
return payload;
}
}
Here we have defined some basic getters and setters for a node. Now if we want to define a class wrapping these nodes, we can do that as well:
public class LinkedList {
private Node head;
public Node getHead() {
return head;
}
public void addToFront(int value) {
head = new Node(value, head);
}
public Node removeFromFront() {
Node remove = head;
head = head.getNext();
return remove;
}
public Node find(int value) {
Node current = head;
while (current != null) {
if (current.getPayload == value) {
return current;
}
current = current.getNext();
}
return null;
}
}
This basic wrapper allows us to get the beginning of the list, add items to the front, remove items from the front, and find items based on some value. Additional functionalities can be added as we’ll see in the subsequent sections.
Indexing
To get a particular element at some index, we need to traverse the list to that index. Because of this, indexing isn’t really a good idea. However, the following code snippet will get it done:
public int getElement(int index) {
Node current = head;
if (current == null) {
throw new IndexOutOfBoundsException();
}
int i = 0;
while (current.getNext() != null && i < index) {
current = current.getNext();
i++;
}
if (i == index) {
return current.getPayload();
} else {
throw new IndexOutOfBoundsException();
}
}
As stated before, we usually don’t think of linked lists in terms of indices. Instead, we simply just track the current node during traversal.
Traversal
With a linked list, we don’t need to know how large the list is to get to the end. However, the following method will get us the size of our list:
public int getSize() {
Node current = head;
int size = 0;
if (head == null) {
return 0;
}
while (current != null) {
size++;
current = current.getNext();
}
return size;
}
This is an important distinction because new developers will often try to iterate over a linked list like it’s an array. This getSize method will drive a simple traversal from O(N) to O(N²) very quickly. The built-in linked list library does account for this issue by keeping track of the size dynamically. As elements are added and deleted and global counter is adjusted.
Insertion
Generic insertion is an O(1) process. That’s because the insertion itself simply requires a rework of the pointers. The traversal is considered a separate operation which we have already deemed as O(N).
public void insertAfter(Node n, int value) {
n.setNext(new Node(value, n.getNext()));
}
Meanwhile, deletion is basically the same process except the pointers get rerouted to skip over the deleted node. Deletion is also an O(1) process.
Summary
That’s it for linked lists! As usual, here’s a breakdown of the typical operations and their Big O estimates.
| Algorithm | Running Time |
|---|---|
| Access | O(N) |
| Insert | O(1) |
| Delete | O(1) |
| Search | O(N) |
From this point forward, we’ll start looking at more advanced data structures like stacks, queues, tree, and hash tables. Get pumped! 😀
Recent Posts
Unc is back to gaming, and I need to clown on Overwatch's 6v6 mode. What do you mean I'm in masters? This cannot be a serious game mode.
I Genuinely Don't Understand Why People Tolerate Hallucinations in AI
If a core feature of generative AI is hallucination, I don't know how we move forward from here. How are y'all still putting up with it?